The AI Sales Reality Check: Robots, Reactions, and the Rising Cost of Inference
When AI stops being a novelty and starts racking up "inference costs," the game changes. Join Govind, Magnus, and Mike H as they dive into AI SDRs, 36-personality Monte Carlo sales simulations, and the impending token economy shaping B2B sales in 2026.

Hey everyone, Govind here.
If you have been following my recent digital exploits, you know I have been deep in the trenches building autonomous AI robots.
In a recent livestream, I sat down with my good friends and regular co-conspirators, Magnus and Mike H, to talk about where this whole AI-driven go-to-market space is heading.
What started as a simple show-and-tell of my new digital assistant quickly spiraled into a profound discussion on behavioral sales simulations, global quality standards, and the harsh economic realities of our new digital lives. Welcome to the frontier of 2026, where the robots are doing the talking, but the inference costs are doing the walking.
Part 1: The Wrench, The Robot, and the NanoClaw Architecture
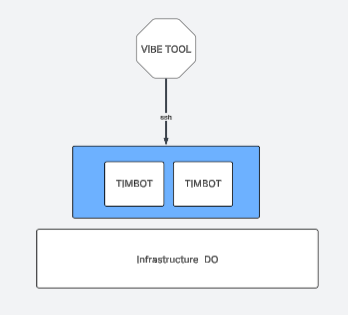
If you want to understand the current state of autonomous AI, you have to look at how we are actually building these things. I have been running my own AI bot from a droplet on DigitalOcean, utilizing an open-source tool called NanoClaw.
For a while, everyone in the tech world was losing their minds over "OpenClaw," calling it a massive breakthrough. And while it was incredibly powerful, allowing the AI to essentially run your machine for you, it presented massive security and configuration challenges because it was not containerized.
When you give a robot the ability to run shell commands and fix itself, you are handing over a level of control that most of us simply should not provide. That realization forced a major architectural shift in how I build and manage these systems. It comes down to a fundamental principle of separation.
 KEY POINT = YOU NEED TOOLING TO WORK ON YOUR BOTS
KEY POINT = YOU NEED TOOLING TO WORK ON YOUR BOTS
The core idea is simple but crucial:
- The autonomous robot must be kept entirely separate from the tooling used to configure and manage it.
- If you give the robot the ability to fundamentally change its own code, you create a massive security problem.
- Instead, you must maintain an outside toolset -- like using Windsurf and SSH to access and configure the robot's capabilities.
- The robot can report on its status, but it cannot alter its foundational nature.
I like to call this the "wrench" philosophy. You have to have a little wrench behind the robot to wind it up. You stay on the outside, winding the machine; it never winds itself.
 INSPIRED BY MIKE H
INSPIRED BY MIKE H
Part 2: Monte Carlo, 36 Personalities, and the "Freeze" Effect
While I was busy building digital containers, Mike H has been working with a European simulation lab to completely redefine how we approach B2B enterprise sales. Mike's project revolves around taking the guesswork out of go-to-market strategies by using highly advanced mathematical simulations to emulate human buyer behavior.
In enterprise sales, you are not just selling to one person; you are navigating a complex buying committee. Mike's lab models up to 36 different distinct personalities that can impact a decision in a Fortune 500 company. This includes everyone from the CXOs and VPs down to the subject matter experts and junior managers.
So, how does a salesperson traditionally approach this? With what Mike calls the "charm approach":
- Salespeople rely on charm and entertainment, believing they can win a room simply by being likable.
- They try to build a friendly relationship before actually understanding the core drivers and decision-making processes of the company.
The problem? This approach introduces immediate friction. When a CXO is approached blindly, their instinct kicks into a fight-or-flight response. But Mike highlights a critical third reaction: The Freeze Effect.
The customer gets shocked, shuts down entirely, and the sales relationship flatlines before it even begins.
To solve this, the lab uses statistical analysis and probability to run massive, event-driven simulations. Instead of relying on old-fashioned A/B testing, they can run thousands of campaign variations in under an hour to find the optimal path.
This is where the heavy data science comes in, leveraging techniques like Monte Carlo simulations and Bayesian analysis. Bayesian forecasting is increasingly used in dynamic business environments to update the probability of a hypothesis (like a buyer responding positively) as more information becomes available.
For the data nerds out there, the underlying logic of Bayesian updating relies on this fundamental equation:
P(A|B) = P(B|A) x P(A) / P(B)
In Mike's simulation world, P(A) is the probability of a successful discovery call, and B is the specific "charm" messaging applied to a distinct personality profile. By running this through thousands of iterations, the AI determines the exact messaging flavor required to keep the buyer in a receptive, "breathing" state.
 PLACE YOUR BETS
PLACE YOUR BETS
Part 3: Magnus, the Cognitive Filter, and ISO 9001:2026
Magnus brought a highly structural perspective to the table, focusing on the intersection of human psychology and global quality assurance. Magnus has been navigating the major updates coming to the ISO 9001 certification in 2026.
The upcoming ISO 9001:2026 revision is expected to build upon the 2015 version, incorporating modern business considerations like quality culture and ethical conduct. Crucially, the update involves an evolution in how organizations assure the quality of digital sales processes and AI implementation. Organizations will need to ensure that their quality policies reflect these new external contexts and strategic directions.
But even with standardizations in place, Magnus pointed out the core hurdle in any sales motion: passing the cognitive "reactional filter".
- The reactional filter is a binary on/off switch; you either instantly grab attention and attraction, or you fail entirely.
- Understanding the specific emotions you need to trigger for a specific personality type is the foundational layer of sales that most humans completely miss.
This is where AI SDRs dramatically change the landscape. When utilizing traditional human sales strategies in a digital format (like sending a video or text automation), you lose the ability to read real-time body language and adjust dynamically. But when you train an AI SDR properly, the dynamic shifts entirely.
| Feature | Human SDR | AI SDR | |---------|-----------|--------| | Consistency | Highly variable based on mood, training, and fatigue | Performs exactly the same on every single interaction | | Cognitive Alignment | Often relies on generic charm; forgets specific persona triggers | Deeply trained on specific personality matrices and knowledge bases | | Scalability | Limited by time and physical energy | Infinite parallel processing capabilities |
Many sales executives are missing a massive opportunity by failing to understand the sheer, unrelenting consistency that an AI representative brings to the table.
Part 4: The Reality Check -- Inference Costs and the Token Economy
All of these simulations, 36-personality matrices, and flawless AI SDRs sound incredible. But there is a massive catch, and it was my biggest realization of the week. As I was happily watching my NanoClaw bot run on its DigitalOcean droplet, I suddenly hit a wall: I was completely out of Claude API credits.
I thought my infrastructure costs were just the $32 to run the server. I was wrong. The real bottleneck in the modern AI landscape is inference cost.
Inference is the execution phase of an AI system; it is the exact moment when the model receives input, consumes compute, generates tokens, and makes decisions. Unlike static software, LLM cost originates during this execution phase. Every time you ask the AI to do something, it tokenizes the request, processes it, and bills you for it.
If you do not aggressively manage these inference costs, you will build an amazing tool that bankrupts you the more you use it. This is the reality of the token economy:
- Agentic AI systems introduce looping, tool usage, and massive context windows, which cause token consumption to skyrocket.
- In multi-turn loops, costs grow quadratically; a 10-cycle reflection loop can consume 50 times the tokens of a single pass.
- To survive the cost of autonomy, systems must employ optimization strategies like prompt caching, which can reduce input costs by up to 90 percent.
- Developers are even creating specialized, highly compact data formats (like TOON) specifically designed to reduce token usage in high-volume AI agent communication.
I had to bump my bot down to the "Haiku" model -- it is faster and cheaper, but it produces lower-quality results. It is a brutal tradeoff. As we build these autonomous agents, we are all becoming victims of the credit economy. We are moving into a world where every digital action is metered.
Conclusion
We are standing on the edge of a massive shift in how businesses operate. From my sandboxed NanoClaw agents trying to safely execute tasks, to Mike's Monte Carlo simulations dodging the "freeze effect" of Fortune 500 buyers, to Magnus preparing for the ISO 9001 mandates of 2026 -- the technology is here.
But as we build these hyper-intelligent, consistent systems, we are all going to have to reckon with the toll booth of the token economy. The real "moat" in AI is not just having the smartest model; it is having the most token-efficient architecture that can turn public information into a competitive advantage without burning through your budget.
Dispatch
Get the next field note
New articles, show notes, and practical lessons from the Strattegys AI crew.
 Agent Development
Agent Development AI Growth Consulting
AI Growth Consulting
Stop Throwing Mud at the Wall
It's 10 PM in Sweden, midday in Texas, and a guy just got caught eating a sandwich on camera. Welcome to The Sarah Factor! Three minds debate: how do you sell in the age of AI? Does the future belong to robots, researchers, or relationship builders? Spoiler: it might be all three.
 Spotlight
SpotlightAI Safety Has a Capital Allocation Problem
AI safety is usually treated as a lab problem. Aligned Institute is making a different bet: the next phase of safety depends on capital allocation, open research participation, operational risk intelligence, and governance systems that can survive contact with real AI deployment.
 Spotlight
SpotlightSee How AI Changes the Calculus for GTM Strategy
Explore a real-life Mirror Teams strategy session showing how AI lowers the barriers to comparing options, testing assumptions, and turning market analysis into executable work.